Computer Organization and Structure
Homework
#6
Due:
2008/1/8
1. A
computer architect needs to design the pipeline of a new microprocessor. She
has an example workload program core with 106 instructions. Each
instruction takes 100 ps to finish.
a. How
long does it take to execute this program core on a nonpipelined processor?.
b. The
current state-of-the-art microprocessor has about 20 pipeline stages. Assume it
is perfectly pipelined. How much speedup will it achieve compared to the
nonpipelined processor?
c. Real pipelining
isn’t perfect, since implementing pipelining introduces some overhead per
pipeline stage. Will this overhead affect instruction latency, instruction
throughput, or both?
2. Consider
executing the following code on the pipelined datapath shown as the following
figure:
add $2, $3,
$1
sub $4, $3,
$5
add $5, $3,
$7
add $7, $6,
$1
add $8, $2,
$6
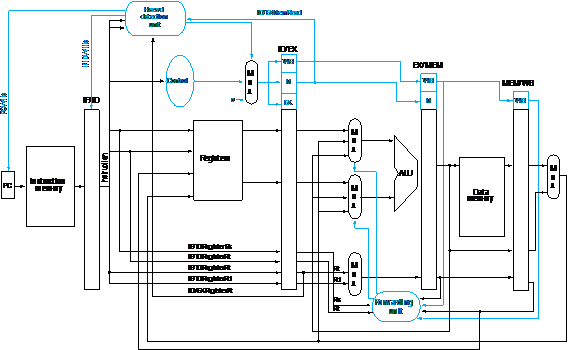
a. At
the end of the fifth cycle of execution, which registers are being read and
which register will be written?
b. Explain
what the forwarding unit is doing during the fifth cycle of execution. If any
comparisons are being made, mention them.
c. Explain
what the hazard detection unit is doing during the fifth cycle of execution. If
any comparisons are being made, mention them.
3. The
following piece of code is executed using the pipeline shown in the following
figure:
lw $5,
40($2)
add $6, $3,
$2
or $7,
$2, $1
and $8, $4,
$3
sub $9, $2,
$1
At
cycle 5, right before the instructions are executed, the processor state is as
follows:
a. The
PC has the value 100ten, the address of the sub_instruction.
b. Every
register has the initial value 10ten plus the register number (e.g.,
register $8 has the initial
value 18ten).
c. Every
memory word accessed as data has the initial value 1000ten plus the
byte address of the word (e.g., Memory[8] has the initial value 1008ten).
Determine
the value of every field in the four pipeline registers in cycle 5.
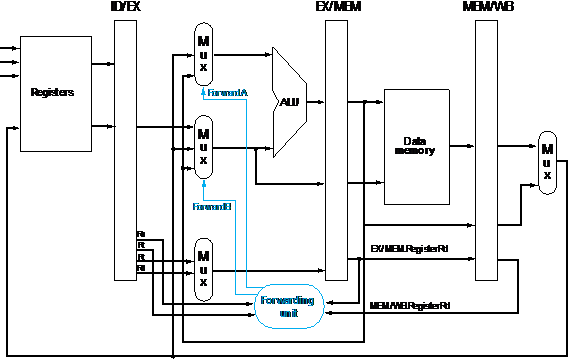
4. The
following code has been unrolled once but not yet scheduled. Assume the loop
index is a multiple of two (i.e., $10 is a
multiple of eight):
Loop: lw $2, 0($10)
sub $4, $2, $3
sw $4, 0($10)
lw $5, 4($10)
sub $6, $5, $3
sw $6, 4($10)
addi $10, $10, 8
bne $10, $30, Loop
Schedule
this code for fast execution on the standard MIPS pipeline (assume that it
supports addi instruction).
Assume initially $10 is 0
and $30 is 400 and that
branches are resolved in the MEM stage. How does the scheduled code compare
against the original unscheduled code?